First off, if you’ve drawn a pretty set of photos for exactly this just point me there with a link please!
I’m trying to better understand the photo processing pipeline PS takes as it relates to HW resources usage.
My understanding, largely from this photo (below), is that the sync process will scan for asset in your non-ps photo library (I’ll call this the messy or unstructured library, mine is…) then for each asset it will run a sha and calculate a mean hash (used for comparisons between images/videos? - guessing a bit here). Then it will create the image’s (or videos) preview sizes/transcode it to be more web friendly, then (or perhaps before the previous step, it will actually pull all the metadata, store it in the db, then place the asset in the appropriate folder in the PS_Library.
My main question
Where does it do each operation on the filesystems? I know there is a temp space that should be on SSD, is that where transcoding/converting/preview creation occurs? Does the hash happen there too, as well as metadata inspection?
The reason I’m asking this is to understand how I might better architect my setup to maximize my hardware’s usage. For example: If tmp really is where all the above occurs, and my messy library is coming off spinning disks and going TO spinning disks then that should prevent my spinning disks from having to handle the IOPS associated with hashing/converting then there likely isn’t much I can do to speed it up beyond faster SSD or maybe even a RAM disk (a little far fetched and would require PS to make a choice of where to conduct its operations, on an SSD or on the RAM disk).
I also was unable to find answers to these questions on the docs so I figured I’d ask the question and either get pointed to the answers or maybe this could be come another resource for googler’s
Thank you in advance, and I do know that if it is all on SSD it’ll be blazing, but thats true for most things (look at the PS5’s SSD requirements for instance), however its also expensive so I wanted to take another stab at seeing if I can tweak anything, move anything, that might speed up ingests. I realize eventually it will finish and I should hopefully not have to ingest again…however we DO have that ML feature coming in the future that might need a complete library scan
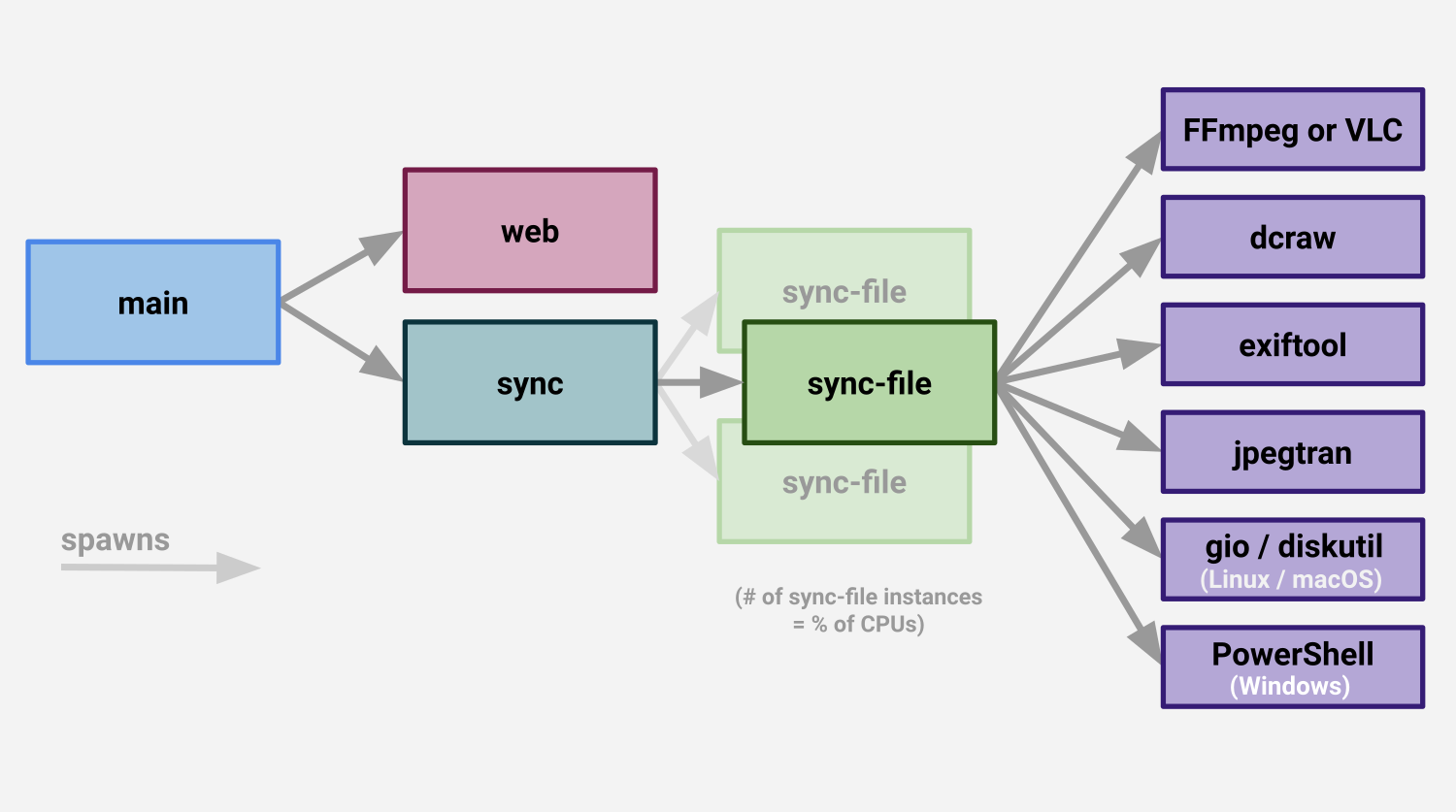
I haven’t drawn a picture of what syncs look like. Here’s a rough sketch:
sync workload
Pop a directory that needs syncing from [...scanPaths, libraryPath]
For each path, recurse and find any file that isn’t hidden and passes “cheap” filters (that we can apply from a stat. Add all these files to a work queue
As sync-files are available to do work, feed them files from these work queues
sync-file workload
sync-file processes are fed file paths, one at a time, to “process.” Processing a file involves:
See if the file is already in the database. This may require a volume UUID to convert the file native path to a cross-machine, cross-platform compatible URI. If there’s an AssetFile that exists with that URI, and the size and mtime match, we’re “done”: it’s a no-op.
De-duplication heuristics then run, which involve looked for the same SHA (but with a different path), or the same image hash and reasonably matching metadata. If no prior assets match, a new one is added.
If “automatic organization” is enabled, and the SHA isn’t already in the library, the file will be copied into the library in a timestamped directory hierarchy.
If the “best” variation has changed for the asset, previews are regenerated.
If the asset is a video, and it needs transcoding, and the asset hasn’t been transcoded already, ffmpeg or vlc is kicked off to do that work
Where does the SHA get performed? On the remote library or in tmp? Same question for the conversions/transcode?
My question is really getting at utilizing the storage IO capabilities where appropriate. I’d much rather have PS copy an asset it’s analyzing to a tmp, RAM disk or ssd, then perform all actions on that asset then continue on its way. Now some folks wouldn’t want that, so I’m trying to understand if PS already does this to some extent and how.
My thinking:
Asset found >> copy to local tmp drive (RAM disk if size appropriate, ssd scratch space if not)
Then perform discovery and create previews, extract metadata, heuristics, add to db.
Then delete the file
Now for the tiny files (below 100MB) a RAM disk makes sense and doesn’t risk destroying an SSD and gives you access to IOPS that are way above anything my remote or local spinning disks can provide.
If you’re already doing this I’ll go sit in the corner and color
I’m trying to also figure out the best build for a dedicated PS server and how I’d want to scale it for cost and capability
Note that /ps/tmp is pretty much only used for raw image conversions (where I can’t tell it to stream to stdout). It used to be for exiftool embedded thumbnail extractions, but I figured out how to do that via streams (no interstitial temp file!)
ExifTool is smart enough to fseek to the “good bits” of a file, and not need to stream the whole thing off disk.
Image hashing (and previews!) frequently can use embedded jpegs, which means, again, a small fraction of the file is streamed off disk.
 so I wanted to take another stab at seeing if I can tweak anything, move anything, that might speed up ingests. I realize eventually it will finish and I should hopefully not have to ingest again…however we DO have that ML feature coming in the future that might need a complete library scan
so I wanted to take another stab at seeing if I can tweak anything, move anything, that might speed up ingests. I realize eventually it will finish and I should hopefully not have to ingest again…however we DO have that ML feature coming in the future that might need a complete library scan 