Apologies! I know how frustrating this is.
I’m finishing up a large update to PhotoStructure that completely changes how library imports work.
what we’ve got now
Currently, sync is in charge of directory iteration, and then spawns N sync-file processes to actually import files into your library.
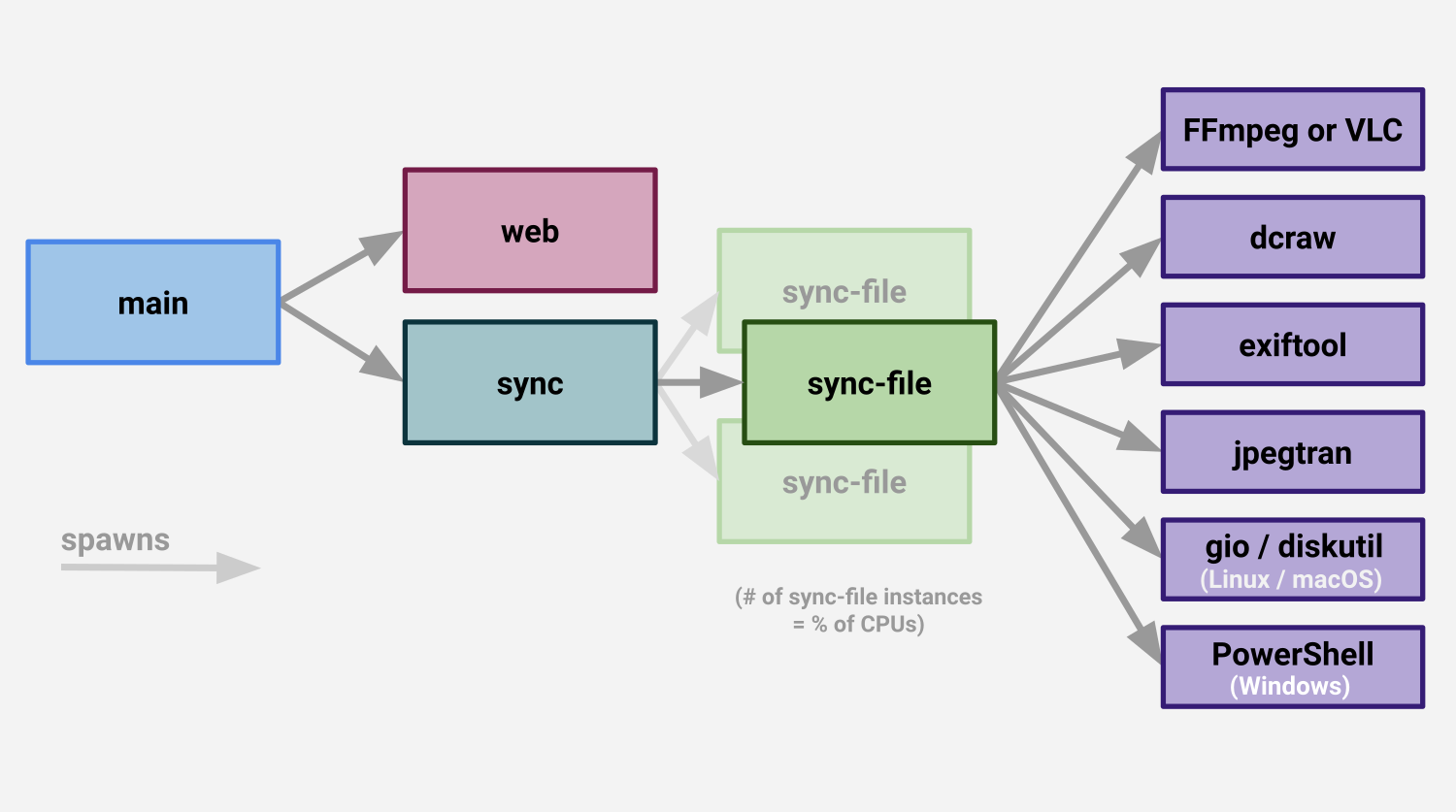
https://photostructure.com/server/photostructure-for-servers/#service-architecture
why that’s problematic
The issue with this approach is that each process is reading and writing to your library database. SQLite’s ability to handle concurrent writes drops precipitously as the size of the database increases (especially when disk I/O is slow), so progress eventually stalls completely in SQLITE_BUSY errors and retries.
how does the new stuff work?
The new approach moves database janitorial work from main to sync, and does away with sync-file sub-processes completely, so only sync and web read and write to your library database. File imports are done within sync, with the majority of non-database work offloaded to worker_threads.
why the original design?
The original design was actually predicated on “not getting stuck,” which can happen if a file is corrupt in such a way that it causes one of the native libraries that PhotoStructure uses to wedge or kill the process, but it seems like the recent worker_thread implementation gives us the same process isolation.
when’s this going to be ready?
My development branch works for smaller libraries on Linux, but I’m still charging down a couple issues on other platforms, and then need to performance test with larger libraries. I hope to release a new alpha branch in a couple of days.