Sorry for this! TL;DR: the next release should address this issue.
If you’re interested in more details, read on:
Last year I stress-tested Version 1.x of PhotoStructure with my 500k+ personal library on my 2-core Intel NUC with an SSD.
Since releasing v1.1, I found that larger or slower libraries (100k+ asset files, or a library on an HDD) had issues on larger-core systems: sync progress would slow down or even stop altogether.
I discovered through system and node profiling that PhotoStructure was “stuck” in disk I/O, and specifically, SQLite mutex operations.
I designed version 1.x with this architecture:
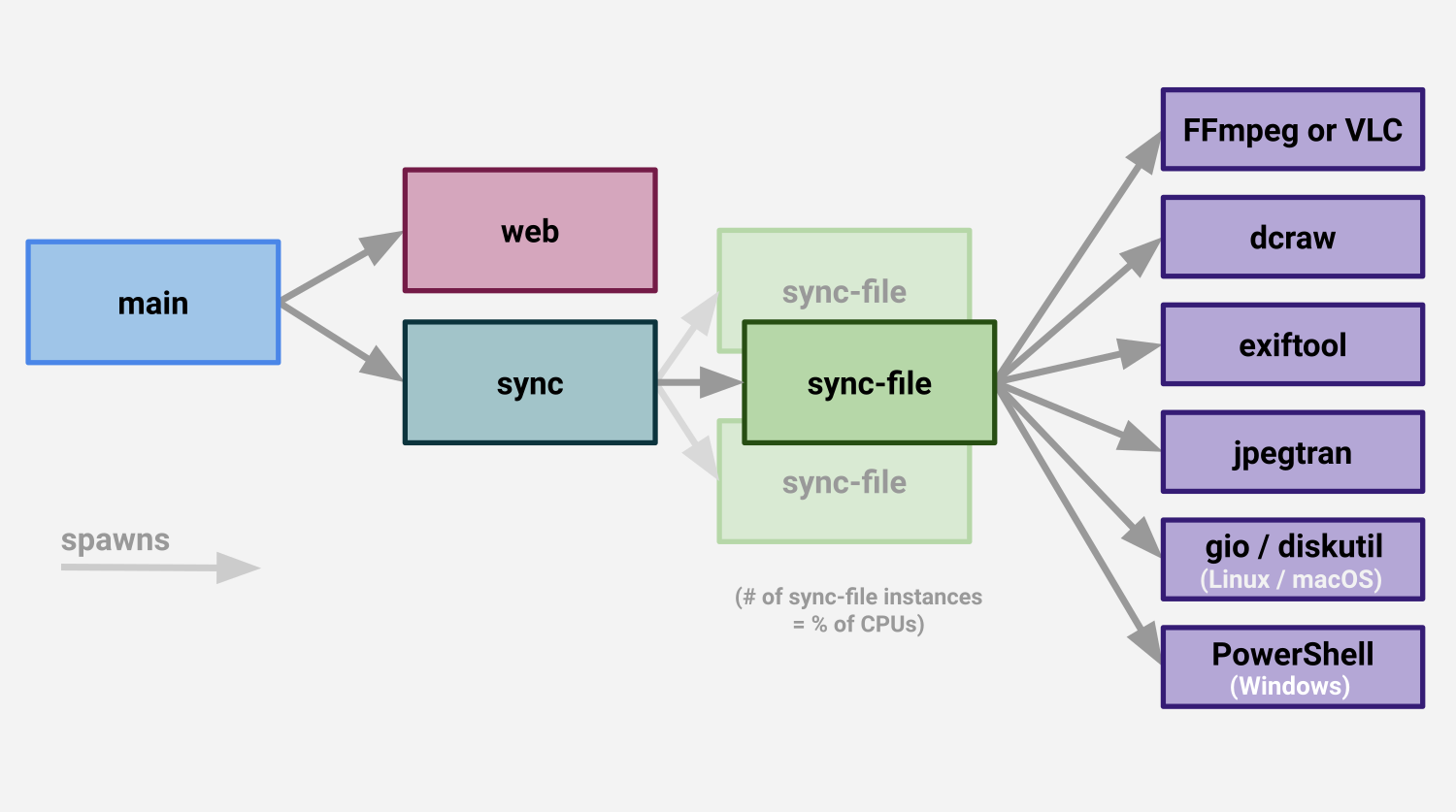
This architecture requires web, sync, and all instances of sync-file to have an open connection to SQLite and the library database.
This works fine as long as the database isn’t large and is on a fast SSD.
Once the library gets larger, or the number of sync-file instances grows, this approach degrades as each process is keeping it’s own copy of the entire database in sync with the disk: tons of CPU is used just in database bookkeeping.
So, last November I tried a different approach: sync would be the only db writer, and smaller subtasks, like image hashing and preview generation, would be offloaded to threads:
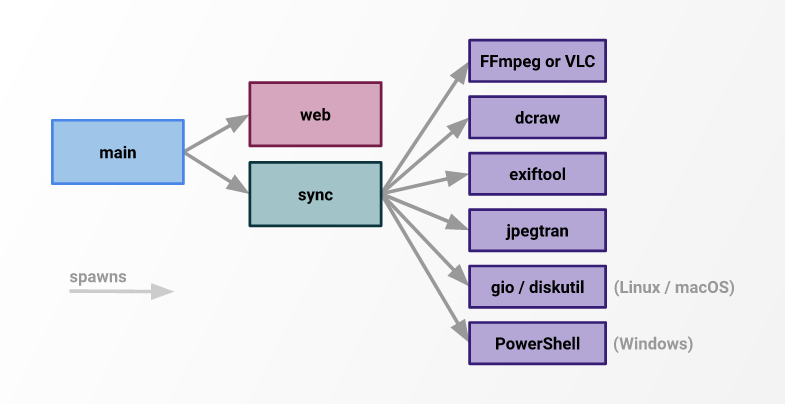
This was promising, but I quickly found that Node.js’s worker_thread implementation still has show-stopping concurrency bugs.
I was able to switch to child processes (thanks to batch-cluster), and that helped, but it took another month of profiling and hotspot remediation before things were  ,
,  and
and  s.
s.
I also added automatic concurrency throttling based on soft timeout rates, so if PhotoStructure finds, say, your NAS doesn’t reply quickly to file operations, it will import fewer files concurrently.
The release notes for the next release include some other related work, as well: https://photostructure.com/about/2022-release-notes/#v210-alpha1